En el mundo acelerado de las finanzas tecnológicas, la precisión y la velocidad son esenciales para manejar transacciones y datos de clientes de manera efectiva. Las empresas fintech, que a menudo manejan pedidos en línea y deben verificar datos contra bases de datos complejas como los Panama Papers o la Clinton List, necesitan sistemas robustos que ofrezcan una vista completa y precisa de sus clientes, conocida como vista cliente 360. En este contexto, el software de data matching se vuelve indispensable, permitiendo la comparación y conciliación de información de manera rápida y precisa.
La Importancia de un Software de Data Matching en Fintech
Las empresas fintech están en constante movimiento, manejando grandes volúmenes de datos que deben ser procesados en tiempo real. Un software de data matching eficiente permite a estas empresas:
- Verificar datos en milisegundos: Crucial para decisiones rápidas y precisas.
- Detectar discrepancias y fraudes: Comparando datos con listas negras como los Panama Papers.
- Mantener una vista unificada del cliente: Esencial para mejorar la experiencia del cliente y tomar decisiones informadas.
¿Qué es el Fuzzy Data Matching?
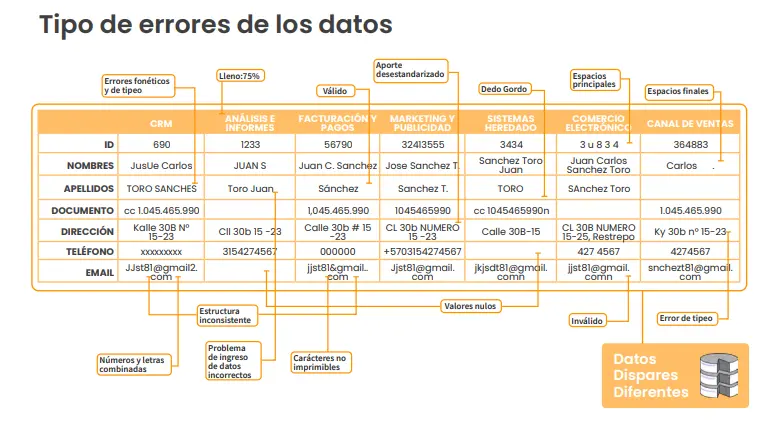
El fuzzy data matching es una técnica que permite identificar registros similares o idénticos dentro de bases de datos, incluso cuando los datos no coinciden exactamente. Esto es especialmente útil cuando los datos pueden variar ligeramente debido a errores tipográficos, diferencias en formatos o incluso abreviaciones.
Ejemplos de Fuzzy Data Matching
- Nombres de personas: John vs. Jonathan
- Números de teléfono: +528556958777 vs. 5569-8777
Estos ejemplos demuestran cómo pequeñas variaciones en los datos pueden complicar el proceso de matching, pero con el uso de algoritmos avanzados, estas diferencias pueden ser reconciliadas para crear un perfil único y completo del cliente.
Algoritmos Clave para el Fuzzy Data Matching
Varios algoritmos se utilizan para llevar a cabo el fuzzy data matching, cada uno con sus propios beneficios y limitaciones. Algunos de los más comunes incluyen:
- Jaro-Winkler: Este algoritmo es particularmente efectivo para comparar cadenas cortas, como nombres o apellidos. Tiene en cuenta no solo las coincidencias exactas, sino también la cercanía de los caracteres coincidentes.
- Levenshtein Distance: Calcula el número mínimo de operaciones necesarias para transformar una cadena en otra. Es útil para detectar errores tipográficos y otras pequeñas diferencias.
- Damerau-Levenshtein: Similar al algoritmo Levenshtein, pero también considera transposiciones de caracteres, lo que lo hace aún más robusto para detectar errores comunes.
Preparación de Datos para Comparaciones Eficientes
Antes de aplicar cualquier algoritmo de data matching, es esencial que los datos estén bien preparados. Esto incluye procesos como la normalización de datos, limpieza y transformación. A continuación, se presentan algunas mejores prácticas para la preparación de datos in-house:
- Normalización: Asegurarse de que todos los datos estén en un formato uniforme. Por ejemplo, estandarizar los números de teléfono a un formato internacional.
- Limpieza: Eliminar duplicados y corregir errores obvios.
- Enriquecimiento: Agregar información adicional para mejorar la precisión del matching, como códigos de país o prefijos telefónicos.
Implementación con APIs y Servicios Web
Las empresas fintech a menudo reciben datos de diversas fuentes, incluidas APIs y servicios web. Estos datos deben ser comparados con bases de datos internas de manera eficiente. Para ello, es crucial contar con un motor de data matching robusto que pueda manejar grandes volúmenes de datos en tiempo real.
Caso de Uso: Implementación de CUBO iQ®

Un ejemplo destacado es el uso de CUBO iQ® API, que permite a las empresas fintech realizar data matching en tiempo real, asegurando que cada transacción esté respaldada por una verificación precisa de datos. Además, la versión en Batch de CUBO iQ® ETL permite a las empresas procesar grandes cantidades de datos fuera de línea, mejorando la calidad y la precisión del data matching.
Beneficios de una Vista Cliente 360 para Empresas Fintech
Una vista cliente 360 proporciona una perspectiva integral de cada cliente, consolidando datos de múltiples fuentes en un solo perfil cohesivo. Esto es especialmente crucial en fintech por varias razones:
- Mejora de la Experiencia del Cliente: Permite personalizar la comunicación y los servicios basados en el comportamiento y las preferencias del cliente.
- Mitigación del Fraude: La capacidad de comparar datos contra listas de sanciones y otros recursos ayuda a prevenir actividades fraudulentas.
- Eficiencia Operativa: Al reducir los errores de datos y las redundancias, se mejora la eficiencia y se reducen los costos operativos.

Desafíos en la Implementación de Data Matching y Vista Cliente 360
A pesar de los beneficios claros, la implementación de sistemas de data matching y la creación de una vista cliente 360 presentan varios desafíos:
- Integración de Datos: La consolidación de datos de múltiples fuentes puede ser compleja y requerir mucho tiempo.
- Calidad de los Datos: La precisión de la vista cliente 360 depende de la calidad de los datos iniciales.
- Cumplimiento Normativo: Las empresas deben asegurarse de que todos los procesos cumplan con las regulaciones de privacidad y protección de datos.
Mejores Prácticas para Data Matching y Vista Cliente 360
Para superar estos desafíos, se recomienda seguir algunas mejores prácticas:
- Adoptar un enfoque iterativo: Implementar soluciones de manera gradual para permitir ajustes y mejoras continuas.
- Invertir en calidad de datos: Priorizar la limpieza y normalización de datos desde el principio.
- Formación y capacitación: Asegurar que el equipo esté bien capacitado en el uso de herramientas y técnicas de data matching.
Conclusión
El software de data matching es una herramienta esencial para las empresas fintech que buscan crear una vista cliente 360. Con la capacidad de comparar datos en milisegundos y detectar discrepancias, estas soluciones no solo mejoran la eficiencia operativa, sino que también protegen contra el fraude y mejoran la experiencia del cliente. Sin embargo, para implementar estas soluciones de manera efectiva, es crucial contar con una preparación de datos adecuada y seguir las mejores prácticas.
Descubre el poder de CUBO iQ® API para el data matching en tiempo real y prueba nuestra versión en Batch con CUBO iQ® ETL. ¡Comienza hoy y transforma la calidad de tus datos!
Te deseamos mucho éxito y no te pierdas nuestros útiles consejos sobre Fuzzy Data Matching para Vista Cliente 360, y más que estaremos subiendo a nuestro canal de youtube https://www.youtube.com/@DatosMaestrosLATAM ¡Esperamos poder ayudarte a alcanzar tus metas de la limpieza de datos y MDM con nuestros servicios y combinado con CUBO iQ® PlataForma de auditoria de Calidad de Datos con un enfoque no invasivo a la solución a problemas comunes sobre la integración de API!
¡Aquí puedes descargar nuestro software gratuito y puedes experimentar, si tienen algun problema o duda, no duden en preguntarnos! Aquí te compartimos tutoriales para que así puedas ¡Empezar Gratis de por Vida!
Preguntas Frecuentes
¿Qué es una vista cliente 360?
Una vista cliente 360 es una visión completa y unificada de un cliente, que combina datos de múltiples fuentes para proporcionar una imagen holística de sus interacciones, preferencias y comportamientos.
¿Cómo ayuda el software de data matching a las empresas fintech?
El software de data matching permite a las empresas fintech verificar y conciliar datos en tiempo real, mejorar la eficiencia operativa, detectar fraudes y proporcionar una mejor experiencia al cliente.
¿Qué es el fuzzy data matching?
El fuzzy data matching es una técnica que permite identificar registros similares o idénticos, incluso cuando los datos no coinciden exactamente, utilizando algoritmos que detectan pequeñas diferencias.
¿Qué algoritmos se utilizan para el fuzzy data matching?
Algunos de los algoritmos más comunes incluyen Jaro-Winkler, Levenshtein Distance y Damerau-Levenshtein, cada uno con su propio enfoque para manejar discrepancias en los datos.
¿Qué desafíos enfrentan las empresas al implementar una vista cliente 360?
Los desafíos incluyen la integración de datos de múltiples fuentes, la garantía de calidad de los datos y el cumplimiento de normativas de privacidad y protección de datos.
¿Qué es CUBO iQ® API y CUBO iQ® ETL?
CUBO iQ® API es una herramienta que permite el data matching en tiempo real, mientras que CUBO iQ® ETL es una solución para procesar grandes cantidades de datos en modo Batch, mejorando la calidad y precisión del data matching.